
When I was a complete beginner and I needed to install something on my Ubuntu machine, I went online and typed in “How to install <software name> on Ubuntu” and it led me to a page with some commands which looked like this
sudo apt-get update
sudo apt-get install <software name>
I was just happy that I was able to type something in the Terminal and it actually worked! I did not pay much attention to what I actually typed in. I guess to beginners, it just feels like a magic spell to get something installed!
As time went on, so many of my google searches led to using very similar “apt” commands to install stuff. Then naturally I started learning more and more about what apt and yum are, what they exactly do and how they do it. This learning process I took, had me go through several books and some “official” hard to read documentations.
In this article, I have tried to explain the concept of package management from a beginner’s perspective so that you can understand the essence of things without going into too many technical details. Once you understand these basics, you should have a good understanding of the fundamentals and you will be able to use these commands with ease!
So let’s begin!
The Fundamentals
Before we could understand the specifics of package managers, we must be able to answer the following question
How does commands work?
Here is a video we made to the answer to the question above!
Now that we have covered the fundamentals lets get back to the topic!
What are packages in a Linux System?
Let’s start with this most basic question. Linux OS is basically made up of 2 parts
- The Linux Kernel and
- Software packages that work with the Kernel to give us a complete Operating System
These packages can be application software like text editors, word processors, etc. or they can be the GNU utilities like bash, cron, dd, etc., or they can be device drivers to talk to the hardware. Everything other than the kernel is a package in Linux.
Next, let’s have a brief look at what is included in these “Packages”
Contents of packages
The content of the packages managed by these package managers involves the following 4 main components
- Binaries or the executable programs
- metadata files containing the version, dependencies, signatures and other relevant information
- documentation and manuals
- configuration files
By keeping these components organized in a certain format, the entire process of installing, updating and uninstalling software can be automated.
Now that we have seen what packages are, let’s go ahead and look at the need for package managers.
Need for Package managers like apt and yum
During the early era of Linux, before we had these “package managers” installing software was a time-consuming process. The process goes something like this
- Download the source code
- Compile it
- Take the produced binaries and put them in proper “bin” folders so that the operating system can find it when invoked
- Take the documentation and put them in the “man” folder so that you can use the “man <package name>” command to get information about packages
- Take the conf files and put them in “/etc/” folder so that you can change settings and configuration of a tool when needed
But this process had a lot of problems as mentioned below.
#1. The Dependency Problem
Softwares have dependencies. Any software you install is built on top of other software and hence they are dependent on the base software to be present in the system for them to run on top of.
That’s just the nature of the Software world. It’s just easier to build on top of an existing system than to reinvent the wheel each and every time!
For example, if you need to run a java-based application, then you need to have a Java Virtual Machine installed first. If you need to run python-based apps, then you need to have the python present. These are just some simple examples.
Practically any software will not just have one dependency, it can have tens and sometimes even hundreds of dependency packages. This posted a need for automating this process of downloading the dependencies along with the packages the end-user needs
#2. The Package Verification Problem
This is the second problem that needs to be solved while installing software. If you noticed carefully sometimes when you are downloading software, there will be some hex-code named “md5” or “SHA” on the download page. For ubuntu downloads, the screenshot below (link) shows such a code
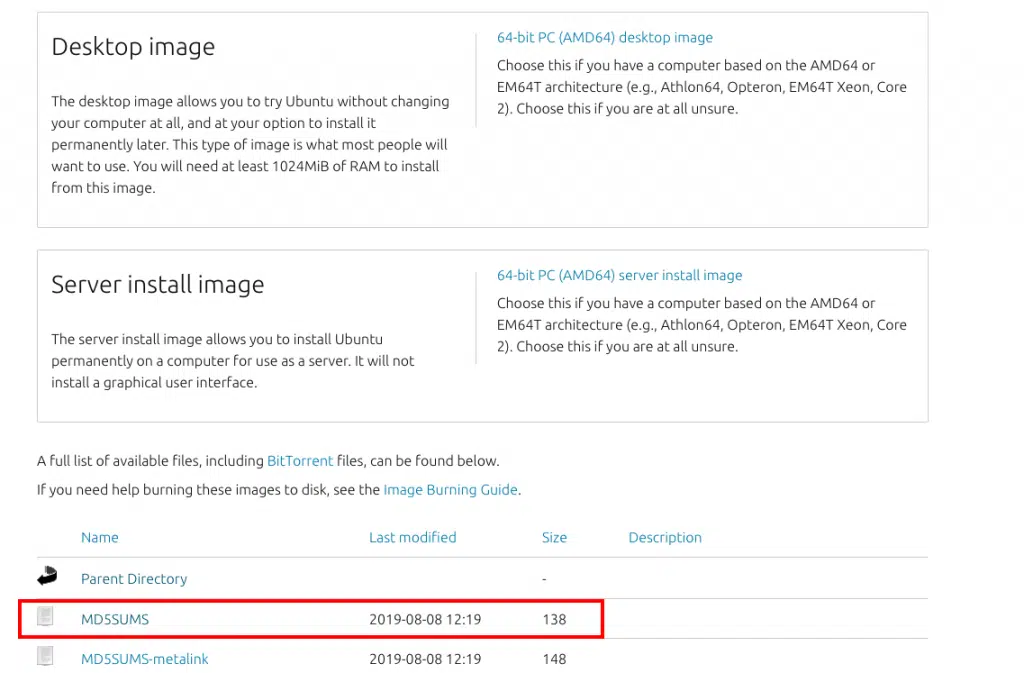
If you click on the link marked by the red square you will be taken to a page which shows the hex-code like this (link)

These are produced by first signing the packages using some keys and then putting them through a hashing algorithm. These can be thought of as signatures used to verify that
- the software you downloaded came through to your system in one piece without any damages from the ubuntu’s (canonical’s) server to your computer and
- the software you downloaded is from the official provider so that you can be sure that there are no malware and other security issues with this software!
This means once downloading any package, you need to manually verify each package’s integrity before you go ahead and install them and verifying each package along with its dependent packages can become a time-consuming process. This is another area where smart automation can help.
#3. The Uninstall Problem
Let’s say we decided to uninstall software since we don’t need it anymore so that we get more space in our hard disk to install more necessary packages. In the olden days, it meant manually going and deleting each of the binary and the dependencies. This can get cumbersome, especially if
- a given package has too many dependencies
- some of these dependencies were shared with other software.
This means deleting a dependency can result in some other software not working properly!
This again posted the need for a smart solution to keep track of software and its dependencies in the system!
#4. The Updating Problem
Software developers come up with bug fixes and feature additions all the time and if you want the latest and greatest, you need to keep your system updated.
In olden days, updating package meant removing and reinstalling it, this basically means we have to jump through all the hoops mentioned above, using the latest version of the software to get things working again!
#5. The Getting Info Problem
In the days before package managers, if you need to know which version of a particular software you are running, you need to look at your own records as there was no built-in system to make note of these details.
#6. The Architecture Problem
Packages are compiled keeping in mind the specific processor architecture we use. A package compiled for a 64-bit system will not work on a 32-bit system. Another example is ARM processors vs Intel/AMD processor. A package compiled for AMD and Intel will not work on an ARM-processor based system. So the system administrator in olden days must also verify that the given package will work on their system!
Thankfully, lots of Linux developers chipped in to make this process of installing and managing software smoother than ever by writing these wonderful tools called Package managers!
Now that we have seen the needs in the olden days that gave rise to this invention of “Package managers”, let’s get back to the present and look at the functions of a present-day software manager in the next section!
Functions of a Package manager
Package managers serve the following functions to fulfill the needs mentioned above
- Automatically resolves dependencies by keeping track of what software is needed to make a package work
- Verifies the integrity of the package before installing it
- Uninstall and update with ease
- Verifies the architecture compatibility
- Keeps track of all the packages installed in the system so that the system administrator can easily get information about what packages are present, when was it installed, what version are they running in, etc.
Next, let’s go ahead and see how these “Packages” are organized to make the job of package managers easier.
Architecture of Package managers
When package managers were first developed, there was only one single level. The 2 of the biggest distro around that time Debian and RedHat developed independently these managers. Debian called theirs dpkg (Debian package manager) and RedHat called their RPM (RedHat Package manager). dpkg used the .deb format to organize these packages and RedHat used the .rpm format.
RPM was very primitive as compared to dpkg such that it could not even resolve dependencies. leaving a lot of work to be done by the end-user. Then this problem was soon addressed and we got another layer on top of rpm known as YUM (stands for Yellowdog Updater Modified) which does more automation to make the life of the system administrator much easier.
Debian’s dpkg tool also evolved over time with layers like apt tools on top of it and that where the famous apt-get command was developed.
Hence these days the package manager software we use are usually multilevel ones, with dpkg and rpm being the lowest level and a level on top to manage these packages more efficiently.
By now I hope you understand what are packages, why we need package managers, what functions they accomplish and the architecture of package managers. Next, let’s go ahead and look at some of the examples of package managers in use today.
Examples of package managers
Most famous ones
| RPM and YUM/DNF | RHEL, CentOS, Fedora and other derivatives of RHEL |
| dpkg and APT | Debian, Ubuntu, Mint and other derivatives of Debian |
Others
| Pacman | Arch Linux and derivatives |
| Portage | Gentoo |
Why there is no App store (like in Mac’s OSX and Windows 10) or an installation wizard (like in previous Windows versions) in Linux?
This is another common question that comes up often with beginners. Why there aren’t any GUI based alternatives to these command-line based package managers?
The answer to this question lies in the nature of businesses that are served by Linux. Linux dominates the server market. More than 95% of the servers are running Linux. Servers as such are professional machines and efficiency is the most important factor there, which means it needs to stay as lean as possible. So Graphical User interface is one of the very first things that are usually removed from these systems and almost all the interactions are done via the command line.
No GUI means no app store or installation wizards
In the Linux desktop arena though, things are slowly beginning to shift towards app store formats. Ubuntu has a software center and Fedora has a software window these days.
But the app collection is very limited in these stores because there are over a million Linux apps and only around one-tenth of them has support for a Graphical User Interface and the rest are designed to be used with the Command Line Interface. Hopefully in the future things will change and more GUI apps will be written to help Linux dominate the Desktop market too!
Related Questions
What are repositories? Repositories (or repos for short) are basically a place where verified packages are stored for easy retrieval by the Package management tools mentioned above. They can be online like the YUM repository or they can be on a local folder or a DVD where you have a special collection of software that you need.
Which is the best package management system? The answer is whichever package manager that came with your distro as default! The reason is the fact that package management tools work hand in hand with the repositories and the official repos have the latest versions of packages precompiled and ready for various different architectures and distro versions so that half the work is done there in the repository itself.
Can you use yum on Ubuntu and other Debian based systems? Yes, you can, but in this case, you need to do the work that the repository does. In other words, you need to compile your own packages and there are not a lot of good reasons to be doing that!
The above answer applies to this next one too.
Can you use apt on Fedora and other RHEL based distros? Yes, you can, but in this case, you need to do the work that the repository does. In other words, you need to compile your own packages and there are not a lot of good reasons to be doing that!
And with that, I will conclude this article!
I hope you guys enjoyed this article and learned something useful.
You can email us or contact us through this link if you have any questions or suggestions.
If you liked the post, feel free to share this post with your friends and colleagues!
Comments are closed.