
In this article, let us learn about the bytes data structure in Python and learn how and when to use it in our Python programs. We’ll also be taking a look at multiple bytes methods that may be useful!
For those of you in a hurry here is the short version of the answer.
Bytes in a Nutshell
The bytes class is a data structure in Python that can be used when we wish to store a collection of bytes in an ordered manner in a contiguous area of memory and we wish for it to remain unchanged.
The bytes class comes under binary data types.
You can use the bytes() constructor to create a bytes object as shown below
numbers = [1, 2, 3, 4]
my_bytes = bytes(numbers)
print(my_bytes)
b'\x01\x02\x03\x04'
Here the syntax we have used is
bytes(iterable_of_ints)
Depending on the type of data we wish to convert into an array of bytes, the bytes class gives us 4 different constructors are shown in the table below.
| Type of Data | Constructor |
| List of integers | bytes(iterable_of_ints) |
| Strings | bytes(string, encoding[, errors]) |
| Bytes | bytes(bytes_or_buffer) |
| Empty Byte Array | bytes() |
| Empty Byte Array of a given size | bytes(int) |
Examples of how to use each one are given further down in the article
The table below shows the most commonly used methods in the ByteArray class
| Method | Meaning |
| decode() | Decodes bytes using the given encoding |
| count() | Returns the number of times a specified substring appears in an array. |
| strip() | Strips or removes specified characters from the beginning or the end of a bytes object. |
| split() | Splits a given bytes object into a list of substrings based on a given delimiter. |
| startswith() | Checks if a bytes object starts with a specific byte or not. |
| endswith() | Checks if a bytes object ends with a specific byte or not. |
| find() | Finds a specific byte or subsequence and return the index of the first occurence |
| index() | Same as find |
| replace() | Replaces all occurrences of a byte with another specified Byte |
Examples of how to use these above methods, along with some more useful methods are given later in the article.
Don’t worry if the above answer does not make sense to you as that was targeted at more experienced programmers who just wanted to refresh their memories. The rest of this article is dedicated to those of you in the first steps of your journey to becoming a Python Craftsman.
By the time you reach the end of this article, I suggest you come back and read this summary once more, I assure you it will make much more sense then!
Feel free to skip to your topic of interest using the table of contents below.
Bytes: A More Detailed Explanation
As explained previously, bytes is just a data structure in Python. Each data structure is useful in solving a particular kind of problem.
The bytes data structure is very useful when we wish to store a collection of bytes in
- an ordered manner
- a contiguous area of memory
- an immutable manner
But when will the above properties of Bytes come in handy?
The bytes class can be used in the following situations where we need to be sending and receiving
- numerical data
- string data
- images in RGB format and
- other binary files
via a communication channel like USB, Ethernet, Wi-Fi, etc. to another device.
For example, say you have a USB microphone recording. That microphone is sending an audio to your Python script. You can receive such audio data in a bytes object and process it by decoding it.
Similarly, you can also use bytes to send out audio to a loudspeaker.
bytes can also be used as a buffer for sending data from your Python script to a Python library for data processing.
For example, say you are writing an image recognition library that processes images. As we know everything in computers is basically stored in 0’s and 1’s. You can receive these images as a bytes object and do the necessary processing.
The bytes datastructure is a good way to pack and process binary data.
This is because bytes store the data given in a contiguous block of memory and hence are very efficient in the above scenarios when it comes to speed.
Discussion on “What bytes are” is never complete without comparison with its cousin “Lists” which is what we will address next!
How do bytes differ from Lists?
Lists can have data placed in different areas of memory, making transmitting data very inefficient. This is because we constantly need to update the addresses of where the next piece of data is and this will cause unnecessary delays in transmission.
The bytes class, on the other hand, have their data placed in contiguous areas of memory and this makes it very efficient to transmit data, as we can simply increment the address to get the next byte of data
Another notable difference is that lists are mutable whereas bytes are not. In other words, you can modify a list after its creation but Python does not allow you to modify a bytes object after you create it.
If the above explanation raises more questions than answers, I suggest you do some research on how lists work in Python.
How do bytes differ from byteArrays?
The primary difference between bytearray and bytes is that bytearray is a mutable type whereas bytes is an immutable type. In other words, a bytearray object can be changed after creation but you cannot change a bytes object once you have created them!
If the concepts of an object being “mutable” and “immutable” are not familiar to you, then I suggest reading our other article on that topic. You can find that in the link below.
Mutable and Immutable Data Types in python explain using examples
Here is a YouTube video we made on ByteArray if you wish to learn more!
When to use which one? bytes vs bytearray
If you are not sure which one to use when, then keep the following rule in mind.
- If you wish to edit something in-place then use bytearray
- If you wish to pass on your data to some other function, which should not modify the data, then use the bytes object.
This is true not only for bytes and bytearray types, but for any mutable and immutable types!
Now that we have learned what bytes are and when to use them, let us go ahead and learn how to use the bytes data structure in our code!
Initializing a Bytes object
The bytes class gives us a variety of constructors to choose from depending upon the type of data we wish to store in our bytes object. They are listed in the table below
| Type of Data | Constructor |
| List of integers | bytes(iterable_of_ints) |
| Strings | bytes(string, encoding[, errors]) |
| Bytes | bytes(bytes_or_buffer) |
| Empty Bytes object | bytes() |
| Empty Bytes object of a given size | bytes(int) |
Storing List of Integers (Iterable of ints)
Lists of integers can be used to represent not just mathematical problems, but also multimedia data like audio, pictures, etc. This is because all data can be boiled down to a list of integers.
Hence integer-list is the most common datatype you will see being used with the bytes class.
You can use the bytes(iterable_of_ints) constructor to create a bytes object from a list of integers as shown in the example below
numbers = [1, 2, 3, 4]
my_bytes = bytes(numbers)
print(my_bytes) #b'\x01\x02\x03\x04'
As we can see,
- 1 becomes 0x01
- 2 becomes 0x02
and so on!
Here the syntax we have used is
bytes(iterable_of_ints)
Let us take another quick example to learn an important concept
numbers = [1, 2, 3, 4, 300]
my_bytes = bytes(numbers)Traceback (most recent call last):
File "/home/main.py", line 2, in <module>
my_bytes = bytes(numbers)
ValueError: bytes must be in range(0, 256)
This time our program crashed with an error.
So why the list [1, 2, 3, 4] work but the list [1, 2, 3, 300] doesn’t work?
This is because a single byte can only contain integers in the range (0, 255) and the integer 300 is outside this range.
Hexadecimals and bytes
1 Byte = 8 Bits
and 8 bits can be arranged in 28 = 256 different combinations which give us numbers from 0 to 255.
- 0 = 0x00
- 1 = 0x01
- 2 = 0x02
- .
- .
- 255 = 0xFF
If you find this concept hard to grasp I recommend researching and learning how hexadecimal numbers work.
Now that we have covered how to convert the most common type of data, i.e. integers to bytes, next let us address the 2nd most common datatype: “Strings”!
Storing a String
When working with strings we can use the following syntax to create the bytes from a string.
bytearray(string, encoding, [, errors])
For example
print(bytes('Python', 'utf-8')) #b'Python'
Here the string “Python” is encoded using the “utf-8” encoding and then passed into the bytes constructor.
How does encoding work?
As we know computers treat everything as 0’s and 1’s. So to represent the letter ‘A’ we can use the byte 0x41, ‘B’ with 0x42, and so on as shown in the table below.
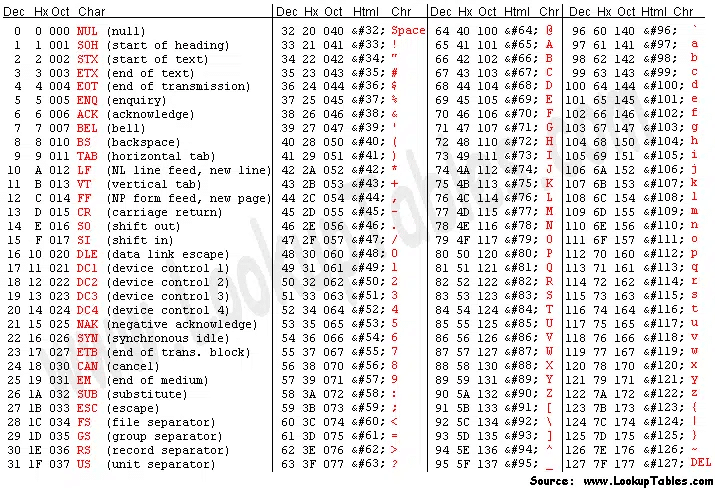
credits: https://www.asciitable.com/
This type of mapping integers to characters is called ASCII encoding. But it is not the only encoding available out there. The latest ones are utf-8 and utf-16 encodings which simply use different numbers to map to different symbols.
Covering different types of encoding is out of the scope of this article, so if you are interested in learning more, I suggest googling!
Let us take another example to see how to use the “errors” parameter.
print(bytes('The price is 100€','ascii', 'replace'))b'The price is 100?'
Notice I have used the Euro character “€” which is not part of ASCII encoding and it got replaced with the “?” (question mark) symbol.
The most common options for the “error” parameter are shown in the table below.
| Value | Meaning |
| strict | Throw an exception in case of error (default behavior) |
| ignore | Ignore the character which could not be encoded |
| replace | Replace the character using the question mark “?” symbol (shown in the example above) |
The code below shows the usage of “ignore” and “strict” options:
print(bytes('The price is 100€','ascii', 'ignore'))b'The price is 100'print(bytes('The price is 100€','ascii', 'strict'))Traceback (most recent call last):
File "/home/main.py", line 1, in <module>
print(bytes('The price is 100€','ascii', 'strict'))
UnicodeEncodeError: 'ascii' codec can't encode character '\u20ac' in position 16: ordinal not in range(128)
As you can see,
- when we use the ignore option, the character which cannot be encoded, the “€” symbol is simply ignored
- when we use the strict option, we get an exception!
Now that we have learned how to use the string constructor of the bytes class, next, let us have a look at how you can convert an object of the Bytearray class into the bytes class.
Converting ByteArray into bytes
Let’s assume you are working with a read-only image and you wish to modify it, then first you need to make an editable copy. Situations like this are where our next constructor comes in.
The ByteArray class is just an mutable version of the bytes class, i.e. an object of the ByteArray class can be modified once created.
This is illustrated in the code below:
#creating a bytearray
myByteArray = bytearray([1, 2, 3, 4])
print(myByteArray) #bytearray(b'\x01\x02\x03\x04')
myByteArray[2] = 4
print(myByteArray) #bytearray(b'\x01\x02\x04\x04')
#converting it to bytes
myBytes = bytes(myByteArray)
myBytes[2] = 4 #you will get a TypeError exception
Here
- we have a ByteArray object named ‘myByteArray’
- We are able to change the 2nd byte in this ByteArray
- If we want to make it unchangeable i.e immutable, we should convert it to a bytes object
- We convert the ByteArray object ‘myByteArray’ to a bytes object ‘myBytes’ using the bytes() operator.
- Now if try to change it, we will get a TypeError with the error message ” ‘bytes’ object does not support item assignment”
- Now the array is uneditable and we can keep it as it is
Here the syntax used is
myBytes = bytes(myByteArray)
So far we have constructed bytes class from data, to end this section let us see how to create an empty bytes object to which we can add stuff later on.
Creating bytes Objects with zeros
If we wish to create a bytes class with X number of elements all initialized to zeros, we can use the following syntax
myArray = bytes(10)
print(myArray)b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00As you can see the array has 10 bytes, all of which are zeros.
Now that we have learned how to create/construct bytes, the next step is to learn how to manipulate values in an existing bytes object.
Manipulating contents of a bytes object
Accessing items in a bytes object
Accessing items in a bytes is the same as in lists, sets, or any iterable. We can access the elements of the bytearray using the index operator.
The index always starts from 0 and the index of the last element is the total number of elements minus 1. Hence accessing elements of the bytes class works the exact same way as the Lists class or the ByteArray class.
Let us see a simple example
mybytes = bytes([0, 1, 2])
print(mybytes[1])1
Here the value at index-1 is the integer 1 and hence it is printed.
Let us next see how to
- add elements
- remove elements and
- make a copy of a Bytes
Adding elements
Adding an element to a bytes object isn’t as straightforward as it sounds. This is because bytes are immutable, we cannot add or remove elements from it.
Don’t lose hope yet! There are ways to do this indirectly.
Let’s say you have an array nums_array:
nums_array = bytes([1,2,3,4,5,6,7,8,9])
And you wanted to complete the array and add the byte representation of 10 to nums_array, what we can do here is, we can reassign a new value to nums_array and add this byte in the process:
nums_array = nums_array + bytes([10])
What we are doing here is, we are creating a new array itself and overwriting it on nums_array.
Here’s what the full program looks like:
#original Bytes array object
nums_array = bytes([1,2,3,4,5,6,7,8,9])
#adding another element to the Bytes array object
nums_array = nums_array + bytes([10])
print(nums_array)
If you’re looking to learn more about appending and if you want to see how to extend the bytes object with other iterables, I suggest reading our other article on that topic. You can find that in the link below:
Python Bytes: Append & Extend, Explained with Examples!
Removing elements
To remove an element from a bytes object, we use the same approach we used for adding an element to a bytes object.
In the following program, we utilize the remove() to remove the b’f’ byte:
#original bytes object
original_bytes = b'abcdef'
#element to remove
element_to_remove = b'f'
#creates a new bytes object and assigns it to the same variable
original_bytes = original_bytes.replace(element_to_remove, b'')
print(original_bytes)b'abcde'In this program:
- We have our original bytes object ‘original_bytes‘
- We wish to remove the element ‘b’f’’ from it
- We use the replace() to replace the byte or element ‘b’f’’ with an empty element ‘b”’
- Now we have a new bytes object, which we then assign to the same variable original_bytes
Here’s another example of removing words in strings:
#creating a byte array with the string 'Hello World'
my_word = bytes("Hello World", "utf-8")
print("Bytes before removal: ", my_word)
#removing the world 'World' by only selecting the word 'Hello'
my_word = my_word[:5]
print("Bytes after removal: ", my_word)
Bytes before removal: b'Hello World'
Bytes after removal: b'Hello'
We utilized indentation to select only the part we needed,
and then simply rewrote it on the original my_word bytes object:

Make a copy of a bytes
Although there are no direct methods to make a copy of a bytes object by using a method such as copy(), there are other ways to achieve this. Let us look at 2 such methods.
Method 1: Using bytes Slicing:
In this method we simply select the whole array and assign it to a new bytes object which becomes the copy.
#creating a new Bytes object
myBytes = b'Hi!'
#creating a copy of the previous Bytes object
myBytesCopy = myBytes[:]
#checking if both of them are equal
print(myBytesCopy == myBytes)
TrueMethod 2: Using the bytes() constructor:
In this method, we simply use the bytes () constructor itself to create a copy
#creating a new Bytes object
myBytes = b'Hi!'
#creating a copy of the previous Bytes object
myBytesCopy = bytes(myBytes)
#checking if both of them are equal
print(myBytesCopy == myBytes)
TrueLooping through a bytes object
As mentioned earlier, a bytes object is iterable. This means that we can loop through it just like any other iterable by using the usual for loop:
myByteArray = bytes([2,4,6,8])
for byte in myByteArray:
print(byte)2
4
6
8
This is particularly useful when you need to perform a function on an array byte by byte.
Other useful bytes methods
The following are a bunch of bytes methods that will be useful when you’re dealing with bytes objects. Let’s go over them briefly one by one:
decode()
Used to decode and convert bytes into strings. You will need to specify the encoding as well along with it.
myBytesArray = b'Embedded Inventor'
print('Before decoding: ', myBytesArray)
myText = myBytesArray.decode('utf-8')
print('After decoding: ', myText)Before decoding: b'Embedded Inventor'
After decoding: Embedded Inventor
In this example, we decoded the Bytes object ‘myBytesArray’ using ’UTF-8’ encoding and converted it into a string and stored it in ‘myText’.
count()
The count() method returns the number of times a specified substring appears in an array.
For example, the byte b‘l’ appears 2 times in the array ‘Hello’:
myBytesWord = b'Hello'
print(myBytesWord.count(b'l'))2Here’s another example counting the number of b’hi’ in a given Bytes object:
myBytesWord = b'Hi there. Hi there once again.'
print(myBytesWord.count(b'Hi'))2strip()
The strip() is used to strip or remove specified characters from the beginning or the end of a Bytes array.
For example, see how the byte b’r’ is removed from the following array:
myBytesWord = b'racecar'
print("Before using the strip() function: ", myBytesWord)
myBytesWord = myBytesWord.strip(b'r')
print("After using the strip() function: ", myBytesWord)Before using the strip() function: b'racecar'
After using the strip() function: b'aceca'
The default character passed is whitespace. This means that if you did not specify what character you want to strip away, it would remove the whitespace from the beginning and/or the end of the array:
myBytesWord = b' Have a nice day! '
print("Before using the strip() function: ", myBytesWord)
myBytesWord = myBytesWord.strip()
print("After using the strip() function: ", myBytesWord)Before using the strip() function: b' Have a nice day! '
After using the strip() function: b'Have a nice day!'
split()
The split() function splits a given bytes object into a list of substrings based on a given delimiter. If you’re familiar with using the split() function with lists, you will find it easier to work with bytes as well.
#creating an array
myBytes = b'red,blue,green'
print('Before splitting the array: ', myBytes)
print('data type: ', type(myBytes))
#splitting the array
myBytes = myBytes.split(b',')
print('After splitting the array: ', myBytes)
print('data type: ', type(myBytes))Before splitting the array: b'red,blue,green'
data type: <class 'bytes'>
After splitting the array: [b'red', b'blue', b'green']
data type: <class 'list'>
In the above example, we used split() with the comma (,) as the delimiter byte. That is why if you look at what we got after splitting it, you will see we have 3 bytes objects: b’red’, b’blue’, b’green’. These are all neatly packed into a list.
Here’s another example to make matters more clear:
#creating an array
myBytes = b'This is an example sentence!'
print('Before splitting the array: ', myBytes)
#splitting the array
myBytes = myBytes.split(b' ')
print('After splitting the array: ', myBytes)Before splitting the array: b'This is an example sentence!'
After splitting the array: [b'This', b'is', b'an', b'example', b'sentence!']
startswith()
The startswith() method can be used to check if a Bytes array starts with a specific byte or not. If it starts with the specified bytes, it returns True, otherwise it returns False.
myBytes = b'Hello World!'
print(myBytes.startswith(b'Hello'))TrueSince the Bytes object ‘myBytes’ started with b’Hello’, we got True as our answer.
endswith()
As you might have guessed, the endswith() method can be used to check if a Bytes array ends with a specified bytes or not.
If it ends with the specified bytes, it returns True, otherwise it returns False.
myBytes = b'Hello World!'
print(myBytes.endswith(b'Hello'))
FalseSince the Bytes object ‘myBytes’ does not end with b’Hello‘, we appropriately got False as our answer.
find() and index()
Both the find() and index() methods are used to find a specific byte or sequence and return the first instances of its index:
myByteArray=bytearray([1, 2, 3])
print("Using the find() method to find the index of 3...")
print(myByteArray.find(3))
print("Using the index() method to find the index of 3...")
print(myByteArray.index(3))Using the find() method to find the index of 3...
2
Using the index() method to find the index of 3...
2
If the given element or byte is not found, the find() method returns -1 whereas the index() raises ValueError:
myBytesArray=bytes([1, 2, 3])
print("Using the find() method to find the index of 3...")
print(myBytesArray.find(50))
print("Using the index() method to find the index of 3...")
print(myBytesArray.index(50))Using the find() method to find the index of 3...
-1
Using the index() method to find the index of 3...
Traceback (most recent call last):
File "/home/main.py", line 7, in <module>
print(myBytesArray.index(50))
ValueError: subsection not found
replace()
The replace() method is used to replace all occurrences of a byte with another specified Byte
For example, have a look at this bytes array:
b'abcdabcdabcd'Let’s say I want to replace all instances of ‘a’ with ‘x’, here’s how that could be done with the replace() method:
myBytes = myBytes.replace(b'a', b'x')Now when I print it, we see that we have got the desired output:
b'xbcdxbcdxbcd'Here’s the full program script:
myBytes = b'abcdabcdabcd'
myBytes = myBytes.replace(b'a', b'x')
print(myBytes)
isdigit()
This method is used to check whether the string contains only digits or not. For example,
myBytes=bytes('123', 'ascii')
print(myByte.isdigit())TrueHere the string ‘123’ is a digit and hence we got True as the result.
isalpha()
This method is complementary to the isdigit() method and it checks if the string is only made up of alphabets as shown below.
myBytesArray=bytes('python', 'ascii')
print(myBytesArray.isalpha())TrueAs you can see, the string ‘python’ is only made up of alphabets and hence we got True as output.So what will happen if a mixture of digits and alphabets are given to the isalpha() method or to the isdigit() method? I leave it to you to experiment and figure it out!
istitle()
This method checks whether a given text is in Title Case (each word starts with an uppercase letter, and the rest of the words are in lowercase).
>>> my_bytes = bytes("This Is A Title", 'utf-8')
>>> my_bytes.istitle()
Truelower()
As the name implies, this method returns a bytes object with all the characters transformed to lowercase as shown below.
myBytesArray = bytes('PYTHON Is awesome', 'ascii')
print(myBytesArray)
myBytesArray = myBytesArray.lower()
print(myBytesArray)b'PYTHON Is awesome'
b'python is awesome'And with that example, I will end this article.
Congratulations on making it to the end of the article, not many have the perseverance to do so!
I hope you enjoyed reading this article and found it useful!
Feel free to share it with your friends and colleagues!
If your thirst for knowledge has not been quenched yet, here are some related articles that might spark your interest!
Related Articles
Python BytesArrays: Everything You Need to Know!
Python: “[:]” Notation Explained with Examples!
Exceptions in Python: Everything You Need To Know!
Thanks to Namazi Jamal for his contributions in writing this article!