
In this article, let us see how to effectively work with strings while using the Bytearray data structure in Python.
A Quick Refresher on Bytearray
ByteArray is a data structure in Python that can be used when we wish to store a collection of bytes in an ordered manner in a contiguous area of memory.
If the “2-line definition” above is causing you more confusion than clarity, then I suggest you read our other article on the basics of ByteArray before continuing this one! You can find it linked below.
Python ByteArray: Everything you need to know!
If you are a visual learner, here is a YouTube video we made on ByteArray!
Coming back to the topic of working with Bytearrays and Strings, let us start our discussion by answering the following question.
Why & When do we need to convert between ByteArray & Strings?
When working with data, you typically find yourself in a situation where you need to convert bytearrays into other forms such as strings.
You may be wondering when/why do we need to convert between strings and bytearrays.
A good example where this conversion between bytes and strings takes place is during “Texting“.
The messages we send are essentially strings of alphabets and other symbols. However, radio signals are not made up of alphabets. Hence somewhere along the way from the moment to hit send till the moment your text reaches the antenna, the text you send gets replaced by 0’s and 1s’.
The same happens in the other direction too, your messaging app receives text as a bunch of bytes, which are then decoded into alphabets and symbols before you can read them.
So in essence, when we send messages it is encoded to bytes to be transmitted to a destination where it is decoded back again to text before you can read them!
The same happens with information in pictures, audio, etc. everything gets encoded into bytes during transmission and decoded back into their original form at reception.
Now that we have understood the “Why & When” parts, next let us switch our focus to coding and see how we can convert between string and bytearray!
Converting string to bytearray
The bytearray class gives us with a number of constructors and each one takes in a different type of object as you can see in the picture below.
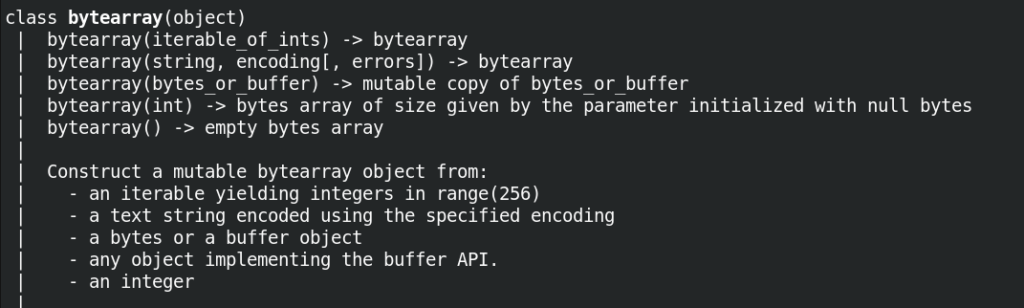
To convert a string to a bytearray, we can simply use the 2nd constructor above and pass it a string-type object.
Here’s a quick example:
Example#1: Using the appropriate constructor
my_string = "This string will be converted to a bytearray object"
my_bytearray = bytearray(my_string, 'utf-8')
print(my_bytearray)bytearray(b'This string will be converted to a bytearray object')The syntax for bytearray() is as follows:
bytearray(string, encoding, errors)This bytearray constructor method takes 3 optional arguments:
- String
- Encoding
- Errors (optional)
- The string parameter takes in the string object that we wish to convert
- The encoding is simply used the let the bytearray() know how we want the string to be encoded. For instance UTF-8 or UTF-16 or ASCII or etc. Encoding is explained in more detail here
- The errors parameter lets the bytearray() know what to do in case the string conversion fails.
This error parameter can take in one of the following values
- ‘strict‘ – This is the default response and raises a UnicodeDecodeError.
- ‘ignore‘ – ignores the part which cannot be encoded using the given encoding.
- ‘replace‘ – replaces the Unicode part that cannot be encoded to a question mark (?) in the result.
- ‘xmlcharrefreplace‘ – this inserts XML character reference instead of unencodable unicode.
- ‘backslashreplace‘ – this inserts a \uNNNN escape sequence instead of unencodable unicode.
- ‘namereplace‘ – inserts a \N{…} escape sequence instead of unencodable unicode.
Let’s look at a few more examples to see how to use effectively use these parmeters:
Example#2: Playing with the ‘encoding’ parameter
Encoding the string to a UTF-8 encoding:
my_string = "Hello"
print("The original string is:", my_string)
my_bytearray = bytearray(my_string, 'utf-8')
print("The encoded string is:", my_bytearray)The original string is: Hello
The encoded string is: bytearray(b'Hello')Encoding the string to an ASCII encoding:
my_string = "Hello"
print("The original string is:", my_string)
my_bytearray = bytearray(my_string, 'ascii')
print("The encoded string is:", my_bytearray)The original string is: Hello
The encoded string is: bytearray(b'Hello')Example#3: Playing with the ‘error’ parameter
Encoding the string with an appropriate response to errors using the errors parameter;
Example#3.1 Ignoring the unencodable code
my_string = "Hello Wörld!"
print("The original string is:", my_string)
my_bytearray = bytearray(my_string, 'ascii', 'ignore')
print("The encoded string is:", my_bytearray)The original string is: Hello Wörld!
The encoded string is: bytearray(b'Hello Wrld!')As we can see, the character ‘ö’ which is not a part of the ASCII code got ignored in the encoded bytearray.
Example#3.2 Replacing the unencodable code with a question mark:
my_string = "Hello Wörld!"
print("The original string is:", my_string)
my_bytearray = bytearray(my_string, 'ascii', 'replace')
print("The encoded string is:", my_bytearray)The original string is: Hello Wörld!
The encoded string is: bytearray(b'Hello W?rld!')This time, instead of ignoring the unencodable character, we replaced it with a question mark ‘?’. This allows developers to notice it and debug it quickly.
Converting bytearray to string
We can convert a bytearray to a string type using one of the str class’s constructors.
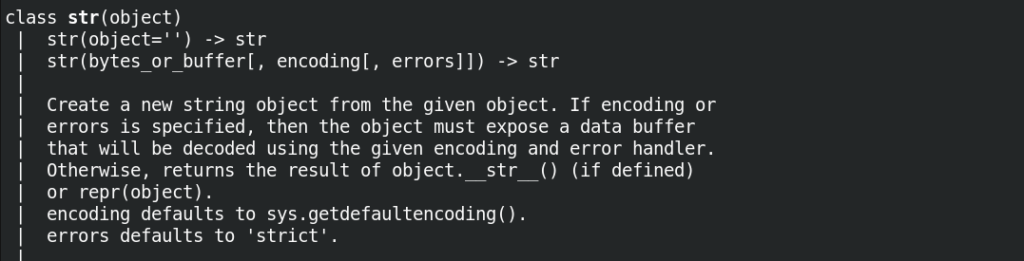
The 2nd constructor above is the one we are interested in. The syntax for str() is very similar to the syntax for bytearray()
str(bytes_or_buffer, encoding, errors)Here’s an example
my_bytearray = bytearray(b'Hello')
print("The original bytearray is:", my_bytearray)
my_string = str(my_bytearray, 'utf-8')
print("The converted string is:", my_string)
The original bytearray is: bytearray(b'Hello')
The converted string is: HelloJust like the bytearray() function, the str() constructor also takes in 3 parameters:
- bytes_or_buffer – this parameter takes in the bytearray object or a bytes object ( you can learn the differences here)
- encoding – That the bytearray object needs to be decoded using (this can be UTF-8, UTF-16, UTF-32, ASCII, etc)
- error – Response when there are some problems with the decoding. This also has the same 6 types of errors just like in the bytearray() function.
Lets look at some examples.
Decoding a normal bytearray string
my_bytearray = bytearray("Embedded Inventor", 'utf-8')
my_string = str(my_bytearray, 'ascii')
print(my_string)Embedded InventorDecoding a numerical bytearray into string
This time, lets make a bytearray using a list of number and see how that can be decoded!
my_bytearray = bytearray([104, 101, 108, 108, 111])
my_string = str(my_bytearray, 'ascii')
print(my_string)helloHere the passed in bytearray was a list of numbers encoded using ASCII
- 104 is ‘h’
- 101 is ‘e’
- 108 is ‘l’ and
- ‘111’ is ‘o’
If the above part sounds confusing, you can learn more about how encoding works here
As you can see, the str() constructor successfully managed to decode our bytearray!
Using the error parameter
Now let’s see what happens if we intentionally pass bytearrays with errors:
Here
- we have a string with the character ö, which is then encoded into a bytearray using utf-8 encoding.
- then we try and decode it back to a string using the ascii mapping instead of utf-8 mapping.
thus intentionally introducing an error.
my_bytearray = bytearray('Embedded Inventör', encoding='utf-8')
my_string = (str(my_bytearray, encoding='ascii', errors='ignore'))
print(my_string)Embedded InventrIf the error parameter was set to ‘ignore’, the character ‘ö’ is ignored and the rest of the characters got printed resulting in ‘Embedded Inventr’
Now let’s try passing in a different error parameter: ‘strict’
my_bytearray = bytearray('Embedded Inventör', encoding='utf-8')
my_string = (str(my_bytearray, encoding='ascii', errors='strict'))
print(my_string)Traceback (most recent call last):
File "/home/main.py", line 3, in <module>
my_string = (str(my_bytearray, encoding='ascii', errors='strict'))
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 15: ordinal not in range(128)This time the str() construcutor tries to decode the ‘ö’ character. Since it cannot be decoded to ASCII, it raises the UnicodeDecodeError and stops the program.
And that is all for today’s article!
Kudos to you for reading the whole thing, only a few have the patience to do so!
I hope you enjoyed reading this article and found it useful!
Feel free to share it with your friends and colleagues!
If your thirst for knowledge has not been quenched yet, here are some related articles that might spark your interest!
Related Articles
Python: bytearray vs bytes, Similarities & Differences Explained!
Python ByteArray: Everything you need to know!
ByteArray: Append & Extend, Explained with Examples
Thanks to Namazi Jamal for his contributions in writing this article!